
かずおじです。AnacondaのPythonでOCRをやってみたので、それについてまとめました。OCRに必要なモジュールのインストールと最低限のコーディングを記載しています。
環境
- MacOS Big Sur 11.2.2
- conda 4.9.2
- python 3.7.9
- tesseract 4.1.1
- pyocr 0.8
必要モジュールのインストール
tesseract
OCRエンジンの一つである。100以上の言語に対応しているよう。
Anacondaでインストール可能。
$ conda install -c conda-forge tesseractPyOCR
tesseractなどのOCRエンジンをラップしているPythonのモジュールである。
以下、githubのドキュメント。
https://gitlab.gnome.org/World/OpenPaperwork/pyocr
Anacondaでは、Windows用のPyOCRモジュールしかないため、pipでインストールする。
$ pip install pyocrOCRを使う最低限のコーディング
対応言語の確認
以下の公式サイトにしたがって設定と対応言語を確認する。
https://gitlab.gnome.org/World/OpenPaperwork/pyocr
from PIL import Image
import sys
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[0]
print("Will use lang '%s'" % (lang))
# Ex: Will use lang 'fra'
# Note that languages are NOT sorted in any way. Please refer
# to the system locale settings for the default language
# to use.<出力結果>
Will use tool 'Tesseract (sh)'
Available languages: afr, amh, ara, asm, aze, aze_cyrl, bel, ben, bod, bos, bre, bul, cat, ceb, ces, chi_sim, chi_sim_vert, chi_tra, chi_tra_vert, chr, cos, cym, dan, deu, div, dzo, ell, eng, enm, epo, est, eus, fao, fas, fil, fin, fra, frk, frm, fry, gla, gle, glg, grc, guj, hat, heb, hin, hrv, hun, hye, iku, ind, isl, ita, ita_old, jav, jpn, jpn_vert, kan, kat, kat_old, kaz, khm, kir, kmr, kor, kor_vert, lao, lat, lav, lit, ltz, mal, mar, mkd, mlt, mon, mri, msa, mya, nep, nld, nor, oci, ori, osd, pan, pol, por, pus, que, ron, rus, san, script/Arabic, script/Armenian, script/Bengali, script/Canadian_Aboriginal, script/Cherokee, script/Cyrillic, script/Devanagari, script/Ethiopic, script/Fraktur, script/Georgian, script/Greek, script/Gujarati, script/Gurmukhi, script/HanS, script/HanS_vert, script/HanT, script/HanT_vert, script/Hangul, script/Hangul_vert, script/Hebrew, script/Japanese, script/Japanese_vert, script/Kannada, script/Khmer, script/Lao, script/Latin, script/Malayalam, script/Myanmar, script/Oriya, script/Sinhala, script/Syriac, script/Tamil, script/Telugu, script/Thaana, script/Thai, script/Tibetan, script/Vietnamese, sin, slk, slv, snd, spa, spa_old, sqi, srp, srp_latn, sun, swa, swe, syr, tam, tat, tel, tgk, tha, tir, ton, tur, uig, ukr, urd, uzb, uzb_cyrl, vie, yid, yor
Will use lang 'afr'「jpn」があれば、日本語に対応しているみたいなのでOK。
画像からテキスト取得(OCR)
以下は、同ディレクトリにあるtest.jpgに対してOCR処理を実施するコードである。
from PIL import Image
import sys
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
tool = tools[0]
txt = tool.image_to_string(
Image.open('test.jpg'),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print(txt)各コードの説明を簡単に記す。
get_available_tools()メソッドにより、使用可能なOCRモデルがリストに格納される。
tools = pyocr.get_available_tools()また、なぜtools[0]を使うかというと、上記で取得した使用可能なOCRモデルが格納されているリストは、推奨順に並んでいるらしい。そのため、tools[0]を使用している。これは公式のREAD.meでも同じことがされている。
tool = tools[0]以下のフォーマットで画像からテキストを取得する。ここのlangを「jpn」にすることで日本語対応にしている。tesseract_layoutというパラメータは指定しなくてもデフォルト値が設定されているが、精度が変わるらしいので、指定してみている。次節で簡単に説明を記す。
txt = tool.image_to_string(
Image.open('test.jpg'),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)tesseract layoutのオプション
このオプションのバリエーションはどこで見れるんだ?ということで模索してみると、ターミナルから以下のコマンドを実行することで確認できることがわかった。
$ tesseract --help-extraデフォルトは3番だが、今回は6の「横方向に一つのブロックでテキストが書いてあるよー」を選択。
<出力結果の抜粋>
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR. (not implemented)
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.実際の結果
以下Wikipediaのスクリーンショットを入力してみると無事にそれなりのテキストが取得できた。
本文はほぼ完璧に読み取れている。すごい。
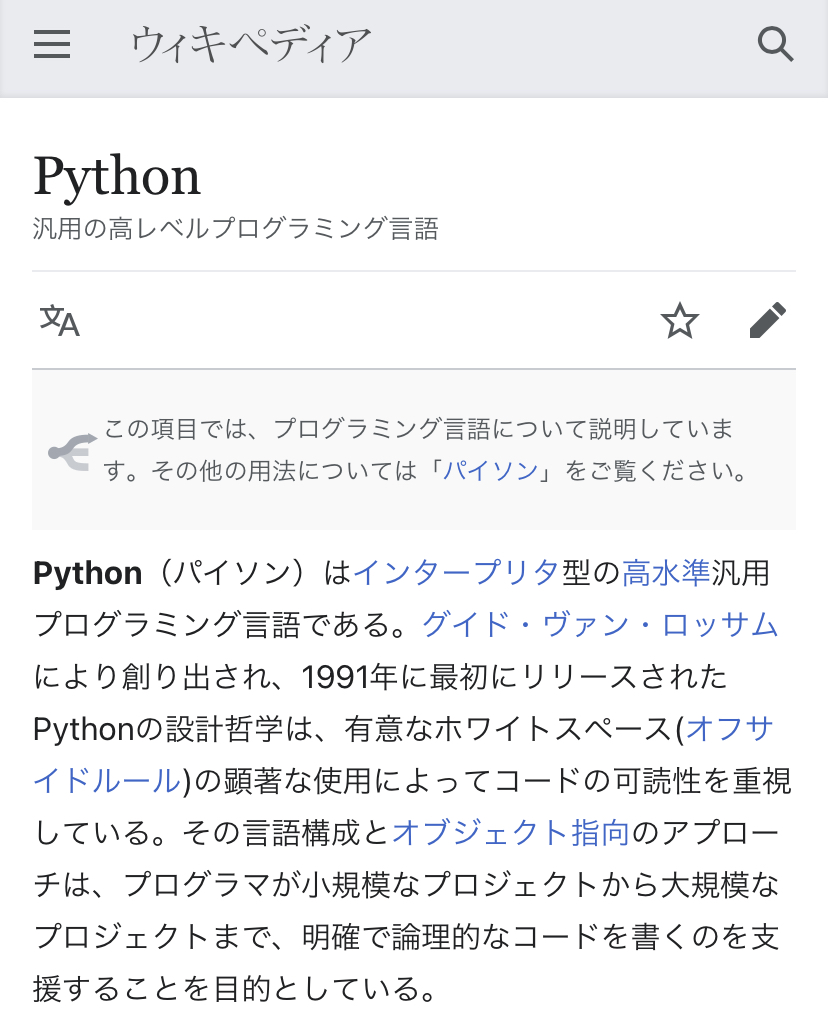
<出力結果>
三 ウィキペディア Q
Python
汎用の高しベルプログラミング言語
入 反 〆
にの項目では、 プログラミング言語について説明していま
す。その他の用法については「パイソン」をご覧ください。
Python (パイソン) はインタープリタ型の高水準汎用
プログラミング言語である。グイド・ヴァン・ロッサム
により創り出され、1991年に最初にリリースされた
Pythonの設計哲学は、有意なホワイトスペース(オフサ
イドルール)の顕著な使用によってコードの可読性を重視
している。その言語構成とオブジェクト指向のアプロー
チは、プログラマが小規模なプロジェクトから大規模な
プロジェクトまで、明確で論理的なコードを書くのを支
援することを目的としている。おわりに
PyOCR、tesseractを使いOCRを試してみましたが、予想以上に簡単で、簡単の割に精度が良い気がします。何か応用できたら、また書きます
参考
tesseract
http://tesseract-ocr.github.io/docs/
PyOCR

